MAI-Thinking-1 Review: Microsoft's Reasoning AI vs GPT-5, Claude & DeepSeek
MAI-Thinking-1 scores 97% on AIME 2025, beats Claude Sonnet 4.6 in human evaluation, and runs on 35B active parameters. Full benchmark breakdown, architecture deep-dive, and enterprise verdict.
At Build 2026, Microsoft quietly did something the AI industry had been waiting for: it stopped being just a distributor. With the launch of MAI-Thinking-1, Microsoft unveiled its first in-house advanced reasoning model — trained entirely from scratch, without distillation from OpenAI or any third-party model. It is arguably the most consequential AI announcement Microsoft has made since it first invested in OpenAI in 2019.
The model is not just a product. It is a signal. Microsoft is no longer content to host and sell other companies’ AI. It intends to build its own.
What Is MAI-Thinking-1?
MAI-Thinking-1 is Microsoft’s flagship reasoning model. Unlike conventional language models optimised for text generation and conversation, reasoning models are specifically built to solve complex multi-step problems — coding, mathematics, logic, and decision-making under uncertainty.
The architecture is a sparse Mixture-of-Experts design with 35 billion active parameters from a total of approximately one trillion parameters. The model supports a 256,000-token context window, making it capable of processing long codebases, legal documents, financial reports, and complex technical specifications without truncation.
Key technical specs at a glance:
| Spec | Value |
|---|---|
| Active parameters | 35B |
| Total parameters (MoE) | ~1T |
| Context window | 256k tokens |
| API compatibility | Chat Completions API |
| Features | Function calling, developer instructions |
Microsoft is explicit about one design choice: “Capabilities should be learned, not inherited.” The model was trained exclusively on clean, commercially licensed enterprise-grade data — no distillation from GPT-4o, no knowledge transfer from OpenAI models.
The Benchmark Numbers
The numbers tell a specific story: MAI-Thinking-1 is not trying to beat every frontier model on every task. It is targeting a well-defined segment — strong reasoning at mid-weight inference cost.
AIME 2025 — Training Progression
The chart below shows MAI-Thinking-1’s AIME 2025 pass@1 score improving from roughly 0.15 at the start of training to near 0.97 by the final checkpoint — a training curve that mirrors what frontier reasoning labs have published for their own models.
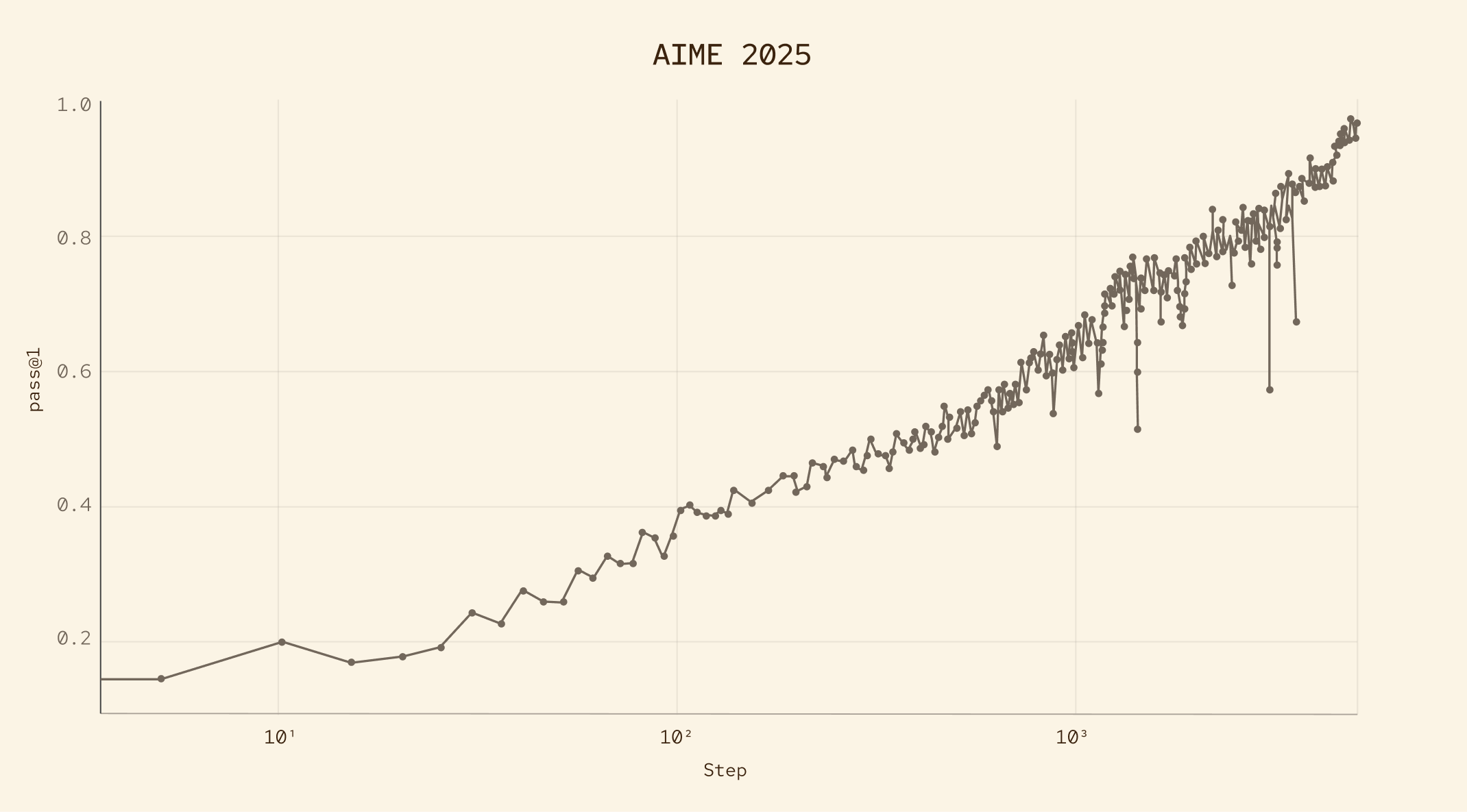
MAI-Thinking-1 AIME 2025 training progression — Source: Microsoft AI
Full Benchmark Table — vs Frontier Models
The table below compares MAI-Thinking-1 against Claude Sonnet 4.6, Claude Opus 4.6, GPT-5.4, Kimi K2.6, DeepSeek V3.2, and GLM-5.1 across STEM and agentic coding benchmarks.
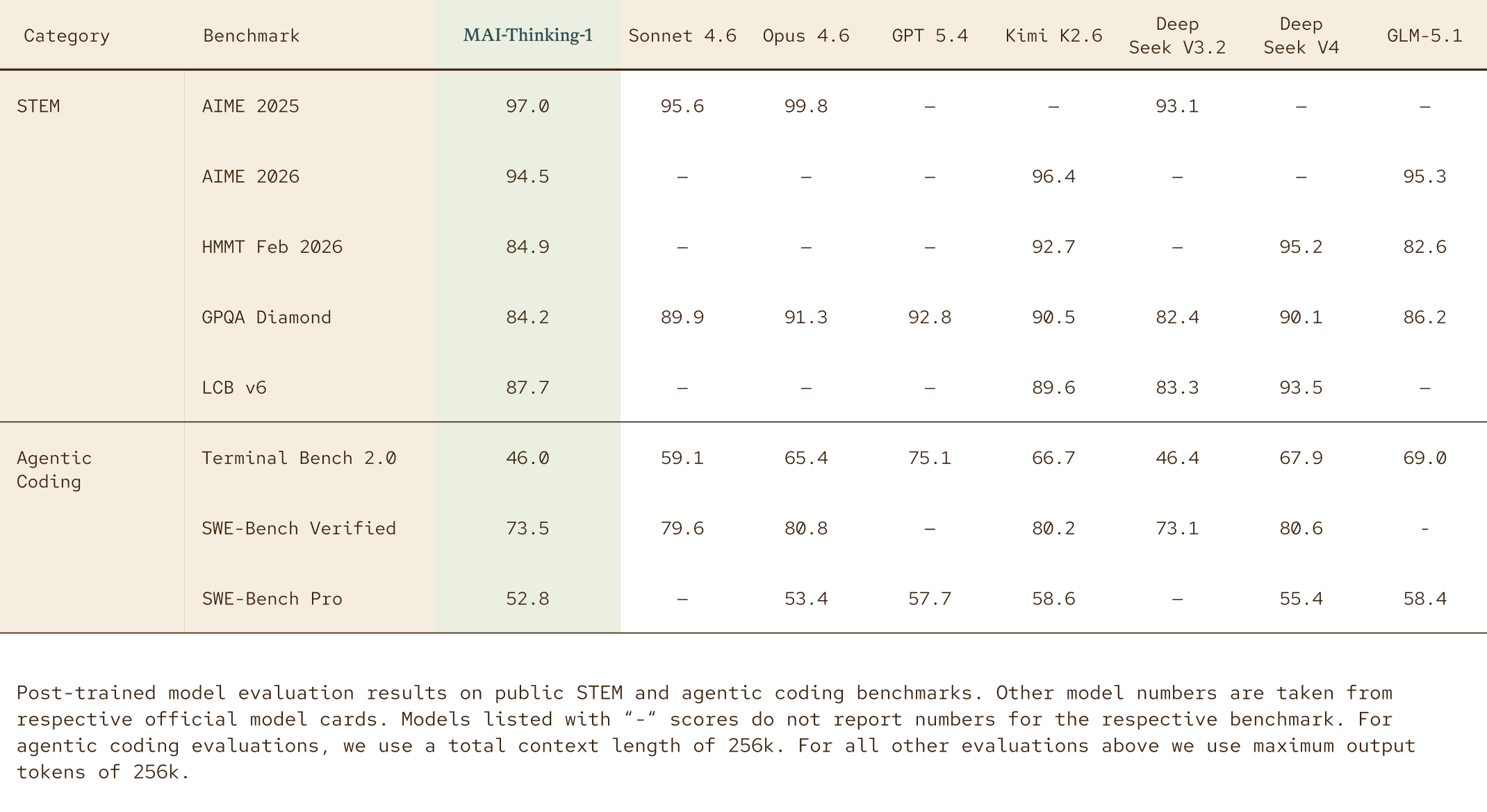
Post-trained evaluation results — Source: Microsoft AI
Reading the numbers directly:
STEM performance:
- AIME 2025: 97.0% (vs Sonnet 4.6: 95.6, DeepSeek V3.2: 93.1)
- AIME 2026: 94.5% (vs Kimi K2.6: 96.4, GLM-5.1: 95.3)
- GPQA Diamond: 84.2% (below Opus 4.6 at 91.3 and GPT-5.4 at 92.8)
- LCB v6: 87.7%
Agentic coding performance:
- SWE-Bench Pro: 52.8% (vs Opus 4.6: 53.4, GPT-5.4: 57.7, Kimi K2.6: 58.6)
- SWE-Bench Verified: 73.5% (vs Sonnet 4.6: 79.6, DeepSeek V4: 80.6)
- Terminal Bench 2.0: 46.0% (below most frontier models)
The honest read: MAI-Thinking-1 leads on AIME 2025 and holds competitive positions in STEM reasoning, but trails the strongest frontier models on complex agentic coding tasks.
Pre-Training Efficiency
The model also demonstrates strong efficiency in pre-training, as shown in the bits-per-byte metrics across held-out code, QA, STEM, and math evaluation sets.
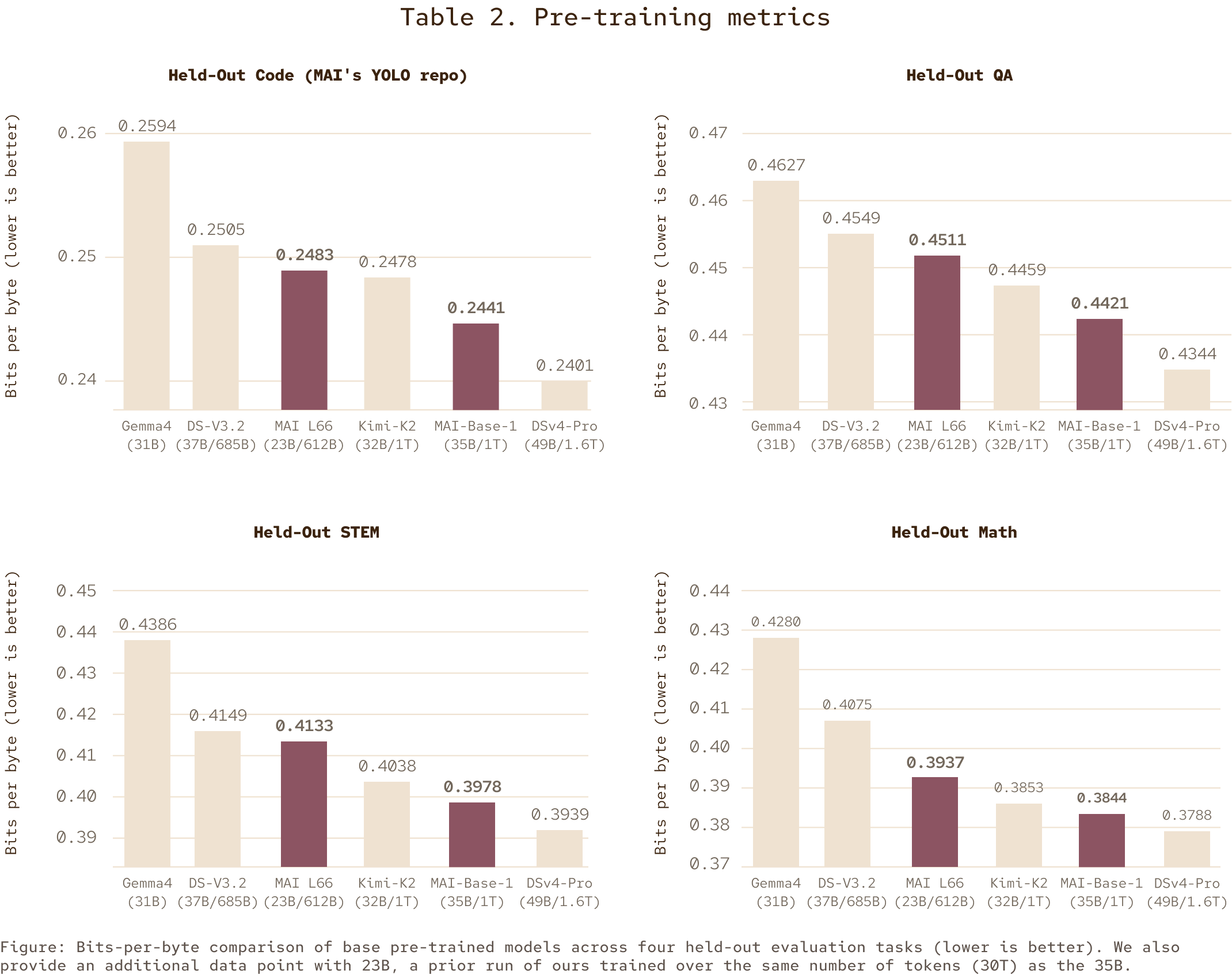
Pre-training efficiency (bits per byte, lower is better) — Source: Microsoft AI
On held-out code, MAI-Thinking-1 (35B/1T) achieves 0.2441 bits per byte — matching or beating models significantly larger in active parameter count, including MAI-Base-1 at 0.2478.
Capabilities should be learned, not inherited. MAI-Thinking-1 was trained on clean, licensed data without distillation from third-party AI models.
Key Capabilities in Practice
Software Engineering
MAI-Thinking-1 integrates directly into GitHub Copilot and Visual Studio Code. For software teams, this means the model is not a standalone tool — it operates inside existing development workflows. Microsoft designed it for debugging, code generation, architecture planning, and technical documentation at enterprise scale.
The SWE-Bench numbers suggest it is competitive but not dominant on complex agentic coding tasks. Where it stands out is the inference efficiency: teams running MAI-Thinking-1 on Azure pay for 35B active parameters, not 1T, keeping costs manageable for continuous development workflows.
Mathematical Reasoning
The AIME 2025 score of 97.0% places MAI-Thinking-1 among the top performers in mathematical reasoning — above Sonnet 4.6 (95.6) and DeepSeek V3.2 (93.1), and within striking distance of Opus 4.6 (99.8). AIME is the American Invitational Mathematics Examination, one of the most widely used reasoning benchmarks in the AI industry.
This level of performance has practical implications for finance, engineering, and research teams that need AI to handle multi-step quantitative analysis reliably.
Enterprise Readiness
Unlike consumer-facing models, MAI-Thinking-1 was built for enterprise compliance from the ground up. Key factors:
- Clean licensed training data — reduces intellectual property risk for enterprise customers
- No third-party distillation — Microsoft owns the model’s intellectual lineage
- Azure-native deployment — operates within existing enterprise cloud agreements
- Compliance-friendly — designed for regulated industries including finance, healthcare, and legal
Why This Launch Is Bigger Than the Benchmark Numbers
MAI-Thinking-1 alone is not the story. The story is what it represents: Microsoft now has a frontier model it built itself.
For years the company’s AI strategy was simple — fund OpenAI, host OpenAI, sell OpenAI. That strategy worked. But it also meant Microsoft’s AI product roadmap was dependent on a company it did not control. Every time OpenAI released a new model, Microsoft had to wait for access. Every time OpenAI changed its pricing or partnership terms, Microsoft’s margins shifted.
MAI-Thinking-1 changes that dependency. Microsoft can now:
- Deploy its own reasoning model on Azure without waiting for OpenAI releases
- Use MAI models in Copilot features where OpenAI integration is costly or restricted
- Offer enterprise customers a model with clear IP provenance and licensing
- Compete in reasoning model segments independent of OpenAI’s product roadmap
Microsoft wants to join the top AI labs alongside OpenAI, Anthropic, and Google DeepMind.
Microsoft’s Broader AI Model Family
MAI-Thinking-1 was launched alongside a family of specialised models:
| Model | Focus |
|---|---|
| MAI-Thinking-1 | Reasoning, STEM, software engineering |
| MAI-Code-1-Flash | Lightweight coding, GitHub Copilot |
| MAI-Image-2.5 | Text-to-image, design-ready output |
| Voice models | Speech synthesis and understanding |
| Transcription models | Audio-to-text at enterprise scale |
This is not a single model launch. It is the opening of a model family strategy — the same approach OpenAI used when it expanded from GPT to DALL-E, Whisper, and Codex. Microsoft is now building its own equivalent ecosystem.
Can MAI-Thinking-1 Compete with OpenAI and Anthropic?
Honestly — not yet on every benchmark. OpenAI’s GPT-5.4 and Anthropic’s Claude Opus 4.6 score higher on complex agentic coding and multi-step reasoning. The GPQA Diamond gap (84.2 vs 91.3 for Opus 4.6) is meaningful for scientific reasoning workloads.
But the frame of “who wins on benchmarks” misses what Microsoft is actually competing for.
Microsoft’s advantages are not model quality. They are distribution, infrastructure, and existing enterprise relationships:
- 400M+ Microsoft 365 users — potential Copilot AI users
- GitHub — the dominant developer platform where MAI-Code-1-Flash lives
- Azure — where enterprise teams already buy compute
- Windows — the operating system where AI will be deployed at scale
In enterprise AI, the company that gets AI into the workflow wins, not necessarily the company with the highest AIME score. Microsoft is already in the workflow.
What This Means for Businesses Evaluating AI
If you are choosing an enterprise AI stack in mid-2026, MAI-Thinking-1 changes a few calculations:
For Azure-native teams: MAI-Thinking-1 is now a viable alternative to Azure OpenAI Service for reasoning workloads — same cloud, lower potential cost, Microsoft-owned IP.
For compliance-sensitive organisations: The clean licensing and no-distillation approach reduces third-party IP exposure in ways that GPT-based models currently cannot match.
For software engineering teams: The GitHub Copilot integration means MAI-Code-1-Flash is already where your developers work. You do not need to change tools.
For general enterprise AI: The benchmark numbers suggest MAI-Thinking-1 is strong at STEM and mathematical reasoning but not the best choice for complex autonomous coding agents — where GPT-5.4 and Kimi K2.6 currently lead.
The right model depends on the specific workload. That is now a meaningful evaluation, where a year ago it was not.
Final Thoughts
MAI-Thinking-1 marks a line in the sand. Microsoft is no longer just the company that made OpenAI possible. It is becoming an AI research organisation with its own models, its own training infrastructure, and its own intellectual property.
The benchmark numbers tell one story — competitive, not dominant. The strategy tells a different, larger one: Microsoft has decided that depending on one AI supplier in a market where the technology is the product is too great a risk. It is building the capability to compete on every dimension.
Whether MAI-Thinking-1 becomes the enterprise reasoning model of choice depends on Microsoft’s ability to close the gap on complex coding benchmarks while leveraging its distribution advantages. The foundation is now there. The race is on.
Frequently Asked Questions About MAI-Thinking-1
What is MAI-Thinking-1?
MAI-Thinking-1 is Microsoft’s first in-house advanced reasoning model, unveiled at Build 2026. It uses a sparse Mixture-of-Experts architecture with 35 billion active parameters from a total of approximately one trillion parameters. It was trained entirely from scratch on licensed data — without distillation from OpenAI, Anthropic, or any third-party model.
How does MAI-Thinking-1 compare to GPT-5?
On AIME 2025, MAI-Thinking-1 scores 97.0% while GPT-5.4 scores above this on GPQA Diamond (92.8 vs 84.2). GPT-5.4 also leads on complex agentic coding benchmarks including SWE-Bench Pro (57.7 vs 52.8) and Terminal Bench 2.0 (75.1 vs 46.0). However, MAI-Thinking-1 leads on AIME 2025 mathematical reasoning and offers a significantly lower inference cost due to its 35B active parameter MoE architecture.
How does MAI-Thinking-1 compare to Claude Sonnet 4.6?
MAI-Thinking-1 outperforms Claude Sonnet 4.6 on AIME 2025 (97.0% vs 95.6%) and was preferred by human evaluators in a 1,276-task side-by-side evaluation conducted by Surge. Claude Sonnet 4.6 leads on SWE-Bench Verified (79.6 vs 73.5) and Terminal Bench 2.0 (59.1 vs 46.0).
How does MAI-Thinking-1 compare to DeepSeek?
On AIME 2025, MAI-Thinking-1 (97.0%) significantly outperforms DeepSeek V3.2 (93.1%). On LCB v6 coding, MAI-Thinking-1 scores 87.7% against DeepSeek V3.2’s 83.3%. DeepSeek V4 leads on SWE-Bench Verified (80.6 vs 73.5) and SWE-Bench Pro (55.4 vs 52.8).
What is the context window of MAI-Thinking-1?
MAI-Thinking-1 supports a 256,000 token context window. This allows it to process full codebases, long legal documents, financial reports, and complex multi-document analysis without needing to truncate input.
How many parameters does MAI-Thinking-1 have?
MAI-Thinking-1 uses a sparse Mixture-of-Experts (MoE) architecture with 35 billion active parameters and approximately 1 trillion total parameters. In MoE models, only a fraction of parameters are active for any given input, which significantly reduces inference cost compared to a dense model of the same total size.
Is MAI-Thinking-1 available on Azure?
Yes. MAI-Thinking-1 is available through Microsoft Azure AI Foundry and Azure AI services. It integrates with the Chat Completions API and supports function calling and developer instructions, making it a drop-in option for teams already using Azure OpenAI Service.
Does MAI-Thinking-1 use OpenAI technology?
No. Microsoft explicitly states that MAI-Thinking-1 was trained from scratch using commercially licensed data, with no distillation or knowledge transfer from OpenAI models. Microsoft’s principle for this model is: “Capabilities should be learned, not inherited.”
What is MAI-Thinking-1 best used for?
MAI-Thinking-1 performs best on: advanced mathematical reasoning (AIME 2025: 97%), software engineering tasks integrated with GitHub Copilot and VS Code, enterprise workloads requiring long-context processing (256k tokens), and compliance-sensitive applications where clean IP provenance matters.
What is the difference between MAI-Thinking-1 and MAI-Code-1-Flash?
MAI-Thinking-1 is Microsoft’s flagship reasoning model designed for complex multi-step problems. MAI-Code-1-Flash is a lighter, faster coding model built specifically for developer tools like GitHub Copilot and VS Code. Code-1-Flash prioritises speed and efficiency for code generation; Thinking-1 prioritises deep reasoning accuracy.
Is MAI-Thinking-1 free to use?
MAI-Thinking-1 is a commercial model available through Microsoft Azure with standard API pricing. Pricing depends on token usage (input and output tokens). It is not available as a free-tier model.
Who built MAI-Thinking-1?
MAI-Thinking-1 was built by Microsoft’s AI research division under the leadership of Mustafa Suleyman, Microsoft’s AI Chief. The model represents Microsoft’s stated ambition to become a frontier AI lab alongside OpenAI, Anthropic, and Google DeepMind.
Benchmark data sourced from Microsoft AI’s official MAI-Thinking-1 announcement. All chart images courtesy of Microsoft AI, used for editorial reporting purposes.


